Respiratory diseases remain a leading cause of global mortality, where timely and accurate diagnosis is critical to improving patient outcomes and reducing healthcare burdens. While prior work has explored audio-based models for respiratory disease detection, such unimodal approaches often suffer from limited generalizability and diagnostic precision. In this paper, we propose RespiraMFM, a Multimodal Foundation Model that integrates respiratory sounds with patient medical history and symptoms to enhance diagnostic accuracy and disease detection capabilities. We introduce an effective contrastive alignment strategy for audio-text multimodal integration, allowing the model to learn better cross-modal representations between respiratory sounds and corresponding textual clinical information. We evaluate RespiraMFM across five major respiratory diseases using seven real-world datasets in both supervised fine-tuning and zero-shot settings, achieving a 9.15% improvement in AUROC on supervised tasks and a 20.98% gain on zero-shot tasks over existing baselines. These findings underscore the potential of our framework to advance early diagnosis and improve clinical decision-making in respiratory disease management.
State-of-the-art performance. RespiraMFM achieves a 9.15% improvement in AUROC on supervised tasks and 20.98% on zero-shot tasks over the strongest multimodal baseline.
Superior zero-shot generalization. RespiraMFM effectively detects unseen respiratory diseases — including asthma and pneumonia — with no disease-specific training samples.
Data-efficient training. RespiraMFM achieves comparable performance with an order of magnitude less training data than baselines, making it ideal for data-scarce clinical settings.
Effective contrastive alignment. The audio-text alignment module consistently improves AUROC across all tasks, confirmed by t-SNE visualization showing cleaner embedding clusters.
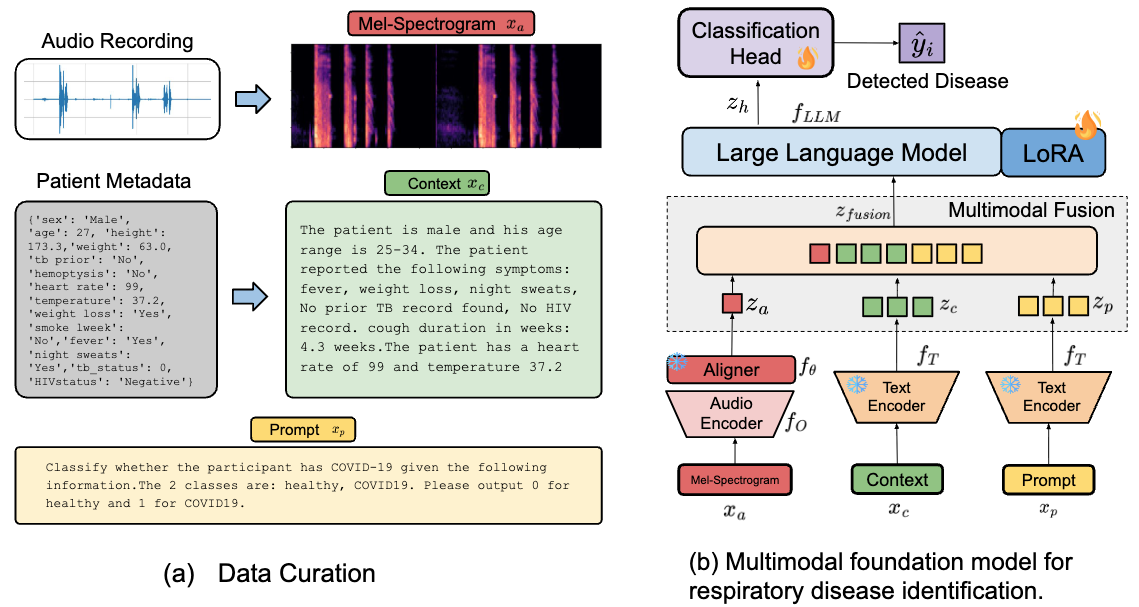
A lightweight MLP projection head is contrastively trained to map 768-dimensional OPERA-CT audio embeddings into the semantic space of the LLM's text encoder. This anchors non-linguistic acoustic biomarkers (coughs, wheezes, crackles) to the correct clinical symptom concepts — providing a semantically aligned initialization before fine-tuning.
The frozen, aligned projector is incorporated into a full multimodal pipeline. Audio embeddings, patient symptom context, and task-specific prompts are concatenated and fed to a 2.7B-parameter Phi-2 LLM fine-tuned with LoRA (rank 16, α = 32) for disease classification via a linear classification head.
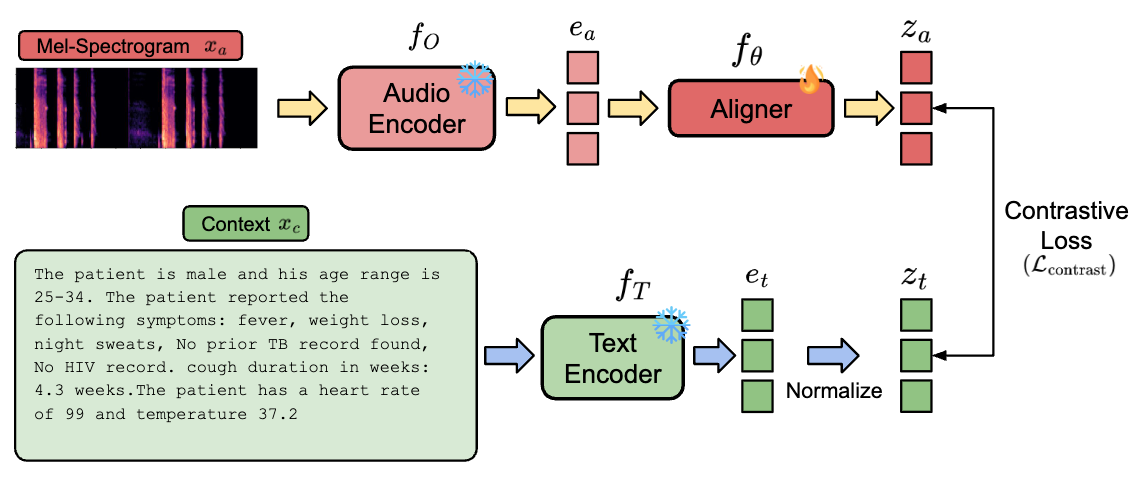
Contrastive learning-based audio-text alignment maps audio embeddings into the LLM's semantic space before instruction tuning.
Class Distribution Across Datasets
| Task | Dataset | Disease | Qwen-2 Audio | BTS | RespLLM | RespiraMFM (Ours) |
|---|---|---|---|---|---|---|
| T1 | UK COVID-19 | COVID-19 | 0.855 ± 0.018 | 0.898 ± 0.010 | 0.881 ± 0.005 | 0.910 ± 0.002 (↑ 1.41%) |
| T2 | Coughvid | COVID-19 | 0.561 ± 0.009 | 0.595 ± 0.014 | 0.613 ± 0.011 | 0.673 ± 0.011 (↑ 9.79%) |
| T3 | TBscreen | TB | 0.334 ± 0.043 | 0.568 ± 0.019 | 0.687 ± 0.016 | 0.709 ± 0.014 (↑ 3.20%) |
| T4 | ICBHI | COPD | 0.614 ± 0.005 | 0.880 ± 0.004 | 0.833 ± 0.007 | 0.999 ± 0.000 (↑ 13.64%) |
| Task | Dataset | Disease | Qwen-2 Audio | BTS | RespLLM | RespiraMFM (Ours) |
|---|---|---|---|---|---|---|
| T5 | Coswara | COVID-19 | 0.813 ± 0.035 | 0.901 ± 0.008 | 0.900 ± 0.006 | 0.908 ± 0.005 (↑ 0.77%) |
| T6 | CodaTB | TB | 0.527 ± 0.012 | 0.645 ± 0.016 | 0.669 ± 0.019 | 0.689 ± 0.012 (↑ 2.99%) |
| T7 | KAUH | COPD | 0.581 ± 0.013 | 0.491 ± 0.014 | 0.425 ± 0.011 | 0.829 ± 0.005 (↑ 42.74%) |
| T8 | KAUH | Asthma ★ | 0.458 ± 0.010 | 0.418 ± 0.016 | 0.399 ± 0.010 | 0.552 ± 0.014 (↑ 20.55%) |
| T9 | KAUH | Pneumonia ★ | 0.301 ± 0.041 | 0.595 ± 0.020 | 0.400 ± 0.021 | 0.709 ± 0.013 (↑ 19.29%) |
| ★ Diseases not seen during training — fully zero-shot evaluation. | ||||||
On the Coswara dataset (T5), combining audio + text consistently outperforms either modality alone across all patient severity groups.
| Input | Mild/None | Moderate | Healthy | Total |
|---|---|---|---|---|
| Audio only | 0.3576 | 0.3571 | 0.7266 | 0.6102 |
| Text only | 0.3294 | 0.6190 | 0.9766 | 0.7934 |
| Audio + Text | 0.4047 | 0.6587 | 0.9849 | 0.8203 |
The contrastive alignment module consistently improves AUC across all zero-shot tasks (T5–T9). Largest gain on unseen COPD dataset: +42.7%.

AUC of zero-shot detection with vs. without contrastive alignment.
@inproceedings{siam2026respiramfm,
title = {RespiraMFM: A Multimodal Foundation Model with Contrastive
Audio-Language Alignment for Respiratory Disease Identification},
author = {Siam, Shakhrul Iman and Feng, Tiantian and Zhang, Jiankun
and Narayanan, Shrikanth and Zhang, Mi},
booktitle = {Proceedings of the 64th Annual Meeting of the Association
for Computational Linguistics (ACL)},
year = {2026}
}